基于 ElasticSearch 开发垂直搜索系统
文章目录
一,背景介绍
ElasticSearch 是由 Lucene 包装上分布式复制一致性算法等附加功能,构成的开源搜索引擎系统。
近两年在业界热度大增,主要有 3 种应用场景:
- 全文搜索引擎
- NOSQL 数据库
- 日志分析数据库 ELK
很多垂直领域搜索需求,都可以基于 ElasticSearch 来设计架构。
ElasticSearch 能大幅度提升相关业务的迭代开发速度,实现类似 sql 数据库增删改查一样的快速开发。 并在相对高 qps 的在线业务中,保证毫秒级的延迟,提供极高的可用性和稳定性。
经过持续的研读官方文档,调研业界经验,并在实践中应用反思后,总结出一套架构方案。供参考,欢迎意见建议。
二,架构方案
一个 ElasticSearch 集群 cluster ,配套:
- 转发代理 proxy
- 队列
1. 转发代理 proxy
proxy 的功能是:
- 协议转换 ,做 rpc 协议如 protobuf 和 ElasticSearch REST json 之间的协议转换, 对文档更新等请求,定义了 rpc 协议,便于队列做各种处理。
- 引入 RPC 框架成熟的负载均衡,容灾,故障屏蔽等功能,到对 ES 的 RPC 中, 比如如果单机 ES 进程挂了,通过返回码让调用方自动换机器重试。
- 统一监控告警系统,监控各种请求失败,延迟分布等,并监控 ElasticSearch java 进程状态,集群状态
- 转发文档更新请求给本机的队列 。用队列做削峰填谷,自动合并批量,做限流。
- 提供双写能力,便于索引升级切换
- proxy 到本机 ES 做了 http 连接池,避免频繁的 HTTP tcp 建连接。
2. 队列
队列 实现了 出队限流,请求合并,削峰填谷 3个功能。
在实际业务中,常常会定期做文档全量更新,会出现短时间内写请求高峰,
如果直接写 ES,请求高峰时,经常出现 ES write 线程池占满,导致部分写请求失败。
另外部分业务每次请求只更新1个文档,导致 ES cpu 高,影响 ES 的写性能,不符合官方推荐做法。
为此,引入队列:
-
配置限制了出队的 QPS ,确保集中高峰被抹平,以匀速稳定地写入 ES,彻底消除了更新失败。
-
并用配置自动把多个请求合并成批量 (比如 5000个文档一个批量),优化了 ES 的写入性能。
-
请求高峰中超出配置 QPS 的请求,队列自动暂存在文件中,随后处理,保证了 ES 服务平稳。
3. 其他工具
另外,繁荣的 ES 开源生态中,周边工具非常丰富便捷, 我们常用的两种周边工具:kinana 和 bin/elasticsearch-sql-cli,极其方便快捷,大幅度提升了开发效率。
三,搜索应用开发优化指南
垂直搜索系统的在线检索部分,一般流程如下
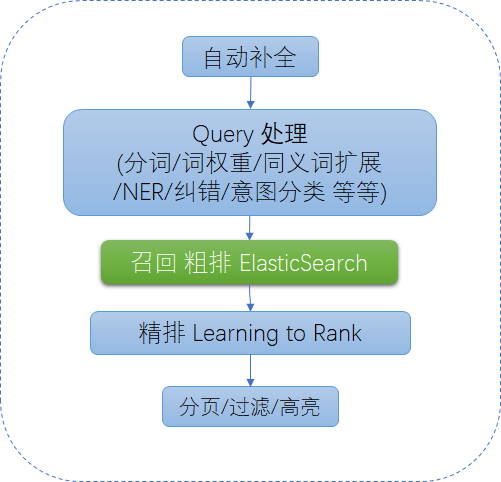
ES 用来实现 召回和粗排环节 ,和部分自动补全环节。
基于 ES 开发的优点:
- ES/Lucene 的 Query DSL 极其强大全面灵活,业务逻辑代码大幅度简化,开发简单便捷,业务迭代开发速度大大提高。
- 有商业公司维护的高质量官方文档, 网上也有海量资料,新人几天就可以上手,快速形成生产力,提升团队效率。
- 成熟稳定,就目前经验看没有遇到过 bug
- 业务如果扩展,后续伸缩性,扩展性,分 shard ,多副本等,都有比较成熟方案。
1. query DSL 语法
基于 ES 的开发,首先需要学习常见的几种 query,
ES 的 query 简单分成 4 类:
- term query,对单个词的 query,包括 term/terms/range/exists/missing/ids/regexp 等
- full text query ,全文检索query,对多个词(即句子)的query,包括 match/multi_match/common 等
- compound query 复合 query,包括 bool/dis_max/function_score 等
- match_all ,简单匹配所有文档
建议先学习 term/match/range/bool ,就可以实现大部分业务逻辑。
网上资料较多,就不转述了。
可以先看看这些中文资料,在 test 环境的 kibana 做做实验,快速上手:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/search-in-depth.html
https://my.oschina.net/yumg/blog/637409
https://www.cnblogs.com/yjf512/p/4897294.html
当然最好的还是官方英文文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html
2. 分词
中文搜索的一个核心议题,就是分词。
ElasticSearch 常用的中文分词是 ik analyzer。ik 是开箱即用,便于小型业务快速开发的。
但是作为对分词可定制性要求较高的业务,我们实际测试,发现 ik analyzer :
- 不支持本地自定义词典文件的热加载;
- 无法针对不同 index 配置不同自定义词典;
- 另外对一些分词的 bad case ,比如没有正确切分的词,没法简单 fix。
因此推荐不用 ik ,而是在更新文档和搜索的时候,在外部做分词,然后用空格拼起来,传给 ES 做索引/搜索。这种方案中,在 ES mapping 中配置成 whitespace 分词器。
外部分词可以用 cppjieba 等,索引分词还可以合并多种分词算法结果提高召回率。
对 cppjieba ,我之前做过内存优化,将内存优化到了 1/100。
另外,索引之前,也有必要做 UTF8 的 normalize,全角转半角,英文大小写统一,和英文的词干提取, mapping 中常用
|
|
这些filter
具体可以参考已有业务代码。
3.关系型搜索
实际开发遇到典型的 one-many 关系型数据上的 query,
比如在某业务中,就遇到这种逻辑,经过调研发现常见有 4 种方案:
-
分开2 个 index : one + many ,分开2次串行 search, 问题: 需要2次延迟大
-
反范式,完全展开,one 的数据追加到每一个 many 文档中, 问题:数据量变大,更新 one 需要用 _update_by_query 如果 one 数据更新频繁,可能导致大量写操作
-
nested ,比如 one 嵌套 many 子文档 问题是:nested 嵌套文档更新需要更新整个 root 文档,即要把整个 one 文档 和含有的 many 文档 select 出来,修改,再写回。 对热门 one 文档, 更新会操作大量数据,并发写还可能 data race。
-
join, has_parent, has_child 把 one 和 many 的所有字段合并到一个 index 中, one 和 many 分别独立更新。
经过实际数据测试 join field 方案, 发现当 one:many = 1:1000万 时, 延迟在 5ms 可以接受,因此目前采用了这种方案。
当然,官方文档指出 join 性能是会慢的,后续也有待实践检验。
4. 粗排相关性打分
Lucene 从 2016年的 6.0 版本开始,默认的相关性算法切换成了 bm25 , bm25 是一种调整过的 tf idf 算法。
这里可以做一简单举例介绍,更深入的介绍可以参见下面文章,以及官方文档:
https://www.cnblogs.com/richaaaard/p/5254988.html
ES 的 explain 对 bm25 算分的过程有详尽的解释,推荐自行实验。
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-explain.html
4.1. BM25 例解
比如某业务的真实数据中,我们在所有文档的 title 这个 field 搜索 “牛奶 ” 这个词,
explain 可以看到,这个 bm25 分数的是这样得来的:
|
|
首先,如果某 field 被多个 term 命中,分别算每个 term 的分数 (PerFieldSimilarity),然后求和,本例子只有1个 term “牛奶”。
每个 term 的分数 PerFieldSimilarity
PerFieldSimilarity = idf * tfNorm
而 idf 表征词的重要程度,与具体文档无关。
idf = log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5))
其中 docFreq 就是本shard 中,有多少个文档含有 “牛奶”, docCount 就是本shard 一共有多少个文档。
|
|
freq 即该 field 中,“牛奶”这个词出现了几次 k1 和 b 都是固定常数。 fieldLength 是当前文档的当前field ,一共有多少个 term。 avgFieldLength 即本 shard 中的所有文档的本 field 的 fieldLength 的平均值
4.2. BM25 shard 调整
实际业务发现,当 index 内文档太少(比如 10w 量级就算少) 时 , 有的词在多个 shard 内,词频分布会出现严重不均匀,可能会导致 bm25 分数产生较大偏差,
实践中的解决办法:
- Search 的 url_parameters 参数填 “&search_type=dfs_query_then_fetch”
- 减少 shard 数
4.3. BM25 similarity 参数调整
如上计算过程可见,bm25 中的 b 参数,是用来给短文档做加权的,即 b 越大,越倾向于给短文档更高的 score, 实际中,和算法同学一起分析后,发现针对我们的某业务,不应该对短文本有太高偏向,所以我们把 b 调整成了 0.3 , 实测发现解决了一批 bad case,用户体验有明显改善。
四,性能优化
计算机程序的性能取决于数据结构和算法, ES/Lucene 中主要有几种数据结构:
- FST
- Posting List ,著名的倒排索引,PForDelta 压缩,支持 SkipList 方式跳跃
- BKD Tree,用来实现 int 和 geo 查询
- DocValues , 以 DocID 为 Key 的列存储
https://zhuanlan.zhihu.com/p/47951652
https://www.elastic.co/blog/elasticsearch-query-execution-order
更深入的理解,我目前也在探索中。
在垂直搜索引擎业务中,用户对延迟非常敏感,一般业界经验认为,良好的用户体验应该是在 ** 200毫秒 ** 内返回搜索结果, 这就意味着 ES 延迟最好控制在 100毫秒之内。
经过我们实际业务发现,决定 ES 延迟的因素主要有:
- 内存是否足够, page cache 是否 cache 了检索过程用到的文件数据
- 具体 query 的优化,类比 mysql query 优化
1. page cache 内存优化
page cache 是决定 ES 延迟的首要因素,用作在线检索服务的 ES , 实际中在线检索的代码路径不能有硬盘 io 访问 (实践证明, SSD也不行)
当 ES 用作在线垂直搜索引擎时,
《查询亿级数据毫秒级返回!牛逼哄哄的ElasticSearch是如何做到的?》 https://zhuanlan.zhihu.com/p/68706615
《ElasticSearch在数十亿级别数据下,如何提高查询效率?》 https://zhuanlan.zhihu.com/p/60458049
实践中,某 index 发现延迟非常高,达到了 1-2秒,用户体验很差。 调查发现,iostat 看下 io util 很高,经常到 80% 90%,单机索引数据文件是 page cache 可用内存的 4倍, 于是降低了副本数,单机数据量减少到 page cache 可用内存2倍后, 硬盘 io 降到了 0 ,延迟一下降低到了 150ms 。
2. int 字段查询优化
业务中常会有一些 int 型的字段,存一些枚举性质的值。 在 10亿以上文档的情况下,实际发现有的会出性能问题。
比如 比如前述业务有1个 int 类型的 filter 字段,实际只有 {0,1} 2种取值,
借助 ES 的 profile ,我们发现搜索 query 93% 的耗时在 filter 字段的 PointInSetQuery 中,
随后发现,针对该业务,只需要返回 filter 为 0 的文档,于是我们在更新文档时,发现 filter 非0 的文档,直接把所有字段都清空,并随后在 query 中去掉了 filter 字段的过滤。
之后发现耗时从 150ms 降到了 20ms。
3. 副本数 replicas num
确定副本数的思路:
- 副本数越小越好。越小,单机数据越少,文件被 cache 的比例越高,性能越好。
- 副本太少会影响可用性。因此必须大于最大能容忍故障单机个数 max_failures 。
综合起来就是:
max(max_failures, ceil(num_nodes / num_primaries) - 1).
num_primaries 是 primary shards 的数量,就是一个 index 有多少个 shards,一般都 > num_nodes
replicas_might_help_with_throughput_but_not_always
对数据量特别少的 index,可以每台机都存一个副本 “auto_expand_replicas”: “0-all”,
4. 多 SSD
在 elasticsearc.yml 的 path.data 配置多个路径,ES 会自动把 shard 均分到多个路径上,如果有多个硬盘,可以充分利用多设备的 io 带宽,当然对在线业务意义不大。
5. 内存配置
最开始我们使用 16G 内存机型, 后来发现出现大量 Elasticsearch Data too large Error 错误,随后发现,解决办法就是换到 64G 内存机型,
改 jvm.options 加大 jvm 的 heap 解决,从 10G 加大到 30G 解决 -Xms30g -Xmx30g
需要注意的是,不建议大于 32G,避免 jvm 的指针压缩优化失效。 可以看 ES 的启动 log 确定
|
|
https://www.elastic.co/cn/blog/a-heap-of-trouble
6. refresh_interval
如网上众多文章所说, refresh_interval 一般都设成了 30秒。
一些参考资料:
- 滴滴 Elasticsearch 多集群架构实践 https://cloud.tencent.com/developer/article/1405404
- 京东到家订单中心 Elasticsearch 演进历程 https://cloud.tencent.com/developer/article/1377194
- 从平台到中台:Elaticsearch在蚂蚁金服的实践经验 https://new.qq.com/omn/20190117/20190117A09ADY.html
- 美团点评旅游搜索召回策略的演进 https://tech.meituan.com/2017/06/16/travel-search-strategy.html
- eBay 的 Elasticsearch 性能调优实践 https://www.infoq.cn/article/elasticsearch-performance-tuning-practice-at-ebay
- 有赞搜索系统的架构演进 https://tech.youzan.com/search-tech-1/
- 有赞搜索引擎实践(工程篇) https://tech.youzan.com/search-engine1/
- 全面理解搜索Query:当你在搜索引擎中敲下回车后,发生了什么? https://zhuanlan.zhihu.com/p/112719984
- elasticsearch初学终极教程: 从零到一 https://kalasearch.cn/blog/elasticsearch-tutorial/